Those who follow my Blog know that I’m specialized in optimization of video streaming. It’s a creative and challenging work, because efficiency in streaming is not only a matter of choosing the best codecs and protocols (because it is probable to have a very limited set to choose from) but it’s more important to have an open mind, a genuine passion for research and devotion to quality.
In short: It’s less important the tool you use than the optimized methods, expertise and vision that guide that tool. 
With a bit of research and original approaches it is possible to achieve higher benifits from optimization of existing codecs than from adopting new codecs, especially when you optimize codecs, streaming protocols and playback strategies synergistically.
This is even more true today because we are experiencing a kind of “stall” in the adoption of HEVC, the current state-of-the-art codec, because of uncertainties linked to multiple patent-pools ambiguity and licensing cost. If HEVC continues to be hampered, the alternative will be to use AV1 but it is still under development and will require many years to spread across a fragmented market. I’m sure this scenario will change, soon or later, but that’s not an alibi to wait and continue to deliver unoptimized H.264 video (or VP9), even because the benchmark of the market, Netflix, it’s anything but motionless!
The benefits of that kind of synergic optimizations are also in the fact that they can be applied in large part to different codecs, so when a new efficient codec will become available, the same techniques will be adapted to the new comer and maybe new specific strategies will be invented.
Synergic Optimizations
I’ve already spoken about “adaptive encoding” logic in this blog post. Here I want only to summarize interesting trending techniques to optimize video streaming services that are gaining traction and that I’ve applied in recent years and I’m trying to improve continuously in my consultancies.
Complexity-Aware Encoding
It has many names. Netflix calls it “Per-Title Encoding”, other call “Adaptive Encoding” or “Content-Aware encoding”. I’ve discussed it extensively here. This approach to optimization has gained traction after the article of Netflix about Per-Title Encoding, but it’s a technique yet to be fully exploited.
Streaming services are quite different and there are various ways to setup a Complexity-Aware encoding pipeline. There are simple ways to extimate complexity but also more complex metrics that take into account multiple variables and models of the HVS (Human Vision System). With such refined approach it is possible to control the level of quality delivered by the encoder and therefore optimize the encoding for a specific purpose.
Such approch can be implemented inside a codec (in loop optimization), or applied externally performing accurate analysis upfront the final encoding (usable only in vod encoding).
The more complex implementation is probably the one that uses Machine Learning to predict optimal parameterizations to achieve the desired result (I’ve worked on this for a client in the last 6 months. More on this in the coming posts…)
Complexity-Aware Delivery
This is a variation of the former. The logic is essentially the same but it is not applied to the encoding (a “standard” encoder can be used), but it’s applied at streaming protocol level. The manifests can be manipulated to obtain specific performances according to the analysis of the “cross” qualities you have in the entire ABR set.
For example, if a segment in an HLS set has a too high quality (measurable with traditional objective metrics or with ML-guided metrics) it is possible (but not exactly easy) to manipulate the manifest so to alter how the player navigate across the renditions.
This approach requires accurate setting of the encoder to produce the desired range of qualities and the delivery is optimized at protocol/manifest level. Not straight-forward as the former but still interesting.
Perception-Aware Streaming
I’m not sure, but maybe I’ve forged a neologism! Perception-Aware Streaming. This refined optimization technique is something I’ve played with for a while. The “streaming” in the name is used to indicate that the technique involves both encoding and delivery. “Perception-Aware” indicates that the encoding and the delivery is performed taking into account of perceptual fenomena, and in particular the angular resolution of HVS.

Again I’ve already introduced the concept in a previous post. Essentially in this technique we create a super set of renditions. A sub set is calibrated for big screens, another sub set for tablet/laptop and a final sub set is calibrated for small screen devices.
Leveraging on a simplified model of HVS, angular resolution and known minimum distance from the screen, it is possible to conceal artefacts and provide an higher sense of detail and at the same time reduces the average bitrate especially on smaller screens. We can mix that with a variation of Complexity-Aware encoding to obtain a highly optimized encoding pipeline.
It’s an interesting topic. I’d like to write more about it if I find some time. I don’t exclude that in the next months I could write whitepapers on this topic for a couple of my clients since I’m going to apply this technique again, but in a more evolved form.
Optimized Heuristic
Optimize encoding with the forementioned techniques leads very often to VBR encoding (capped, controlled in some more sofisticated ways or also unconstrained sometimes). Such files require dedicated heuristic to properly execute Adaprive Bitrate Streaming.
In recent times, more optimized and efficient heuristics have emerged compared to the traditional bandwidth-based heuristics. Buffer-based or hybrid heuristics allow a much better exploitation of bandwidth, more resilience to bandwidth fluctuations and can cope easily with VBR renditions. Stay tuned to know more about it.
Conclusion
Taken alone, each of that optimization schema provides interesting benefits, but the real gain is when you can optimize them synergistically. Those strategies are strictly correlated and can strengthen each other and enable new levels of efficiency.
For example, complexity-aware encoding and perception-driven streaming are more efficient when you can encode in VBR, but VBR encoding requires a player with custom and optimized heuristic, in return, a custom heuristic not only can cope with VBR but can also implements more efficient ABR handling and contributes greatly to maximization of QoE.



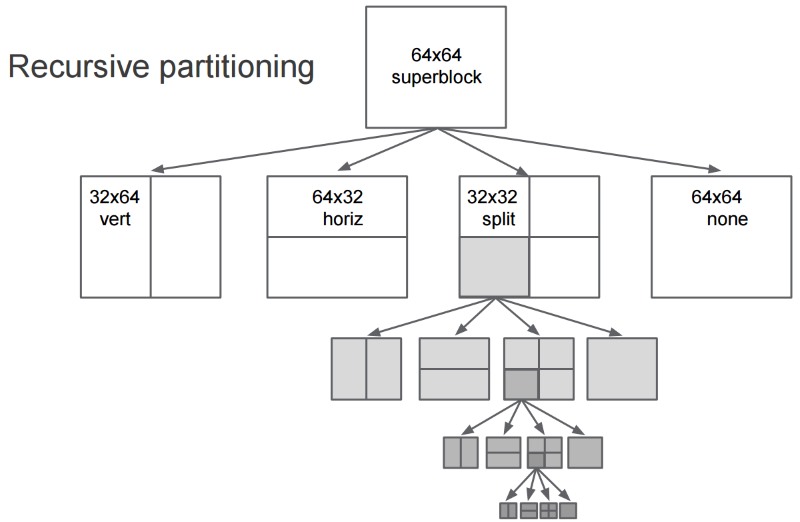

 Making a parallelism between this problem and the encoding, approximate with a 0-order estimator is similar to encode everything with the same resolution-bitrate “mix” (a.k.a ABR ladder).
Making a parallelism between this problem and the encoding, approximate with a 0-order estimator is similar to encode everything with the same resolution-bitrate “mix” (a.k.a ABR ladder).