A technical primer
VP9 is a modern video codec developed by Google as the successor of VP8. While VP8 was aimed at offering an open alternative di AVC (aka H.264), VP9 challenges the latest HEVC (aka H.265). Google follows with VP9 the same model of “open” codec used for VP8 (the fact to be really open and free from patents related threats is still object of debates) and this theoretically makes of VP9 an interesting alternative to HEVC which is burdened by unclear and unsettled claims by multiple patents holders and patent pools.
VP9 specification has been freezed in June 2013 but only recently it is starting to attract attention of players that want to optimize video distribution (Youtube has been the only big adopter during last year, but now also Netflix is evaluating to use it). This is because VP9’s and HEVC’s ecosystems have finally reached a minimum level of maturity and is now possible to do evaluations and comparison with a sufficient level of confidency.
In this short serie of blog posts I analyze VP9 and try to understand if it really deserves attention and why. In this first part we will take a look at the technical specifications compared to HEVC (analyzed in this previous post) and in the second part I’ll analyze the actual performances, limits and contexts in which is possible to use VP9 as a valid alternative to AVC or HEVC.
Picture Partitioning
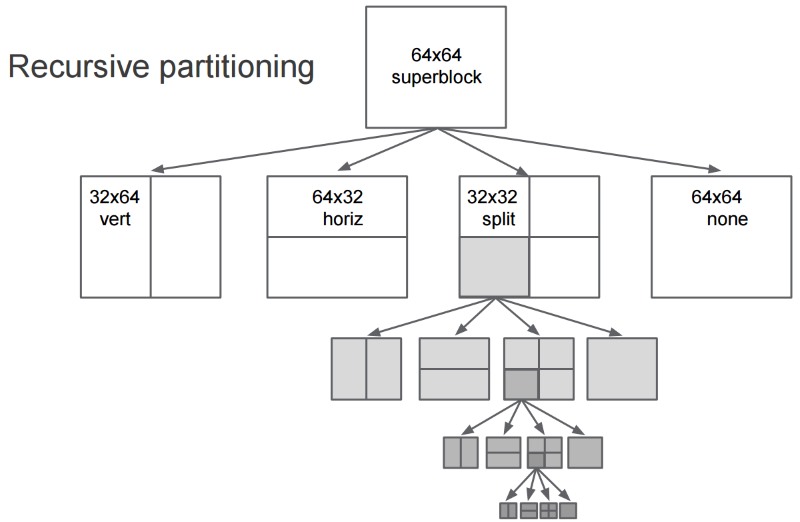
VP9 subdivides the picture in “super blocks”. Similarly to HEVC, in VP9 super blocks can be recursively divided in smaller blocks down to 4×4. Differently from HEVC that can subdivide only in square sub partitions (32×32, 16×16, 8×8) VP9 can also use not square partitions like 32×16, 8×16 and so on (the use of rectangular partitions stops subdivision in the quad-tree branch). Most decisions are taken at level 8×8 (“skip” signaling for example) and 4×4 is a special case of 8×8. prediction mode, reference frame, MV, transform types are specified at block level.
Entropy coding
Like VP8, VP9 uses an 8bit arithmetic coding engine known as the bool-coder. It use a static per-frame statistical model compared to an adaptive stat model like cabac used in AVC/HEVC. For each frame, the more convenient statistical model is choosen from a pool of four.
Residual coding
Similarly to H265, VP9 uses 4 transform sizes: 32×32, 16×16, 8×8 and 4×4. Transformations are integer approximations of DCT (Discrete Cosine Transform) or DST (Discrete Sine Transform), a mix of the two are used depending by the type of frame and transform size. Coefficients are scanned with particular patterns (different from the zig-zag patterns of H26x codecs, but with the same logic).
Quantization
VP9 uses 4 scaling factors: a couple for Luma DC and AC coefficients, and a couple for Chroma DC/AC. The set of quantizers are fixed at frame level, so there is no block-level QP adjustment contrary to AVC/HEVC (but the not mandatory feature “segmentation” should be able to achieve the same effect of an adaptive quantization).
VP9 supports also a special lossless mode that uses only a Walsh transform on 4×4 blocks.
Intra-prediction
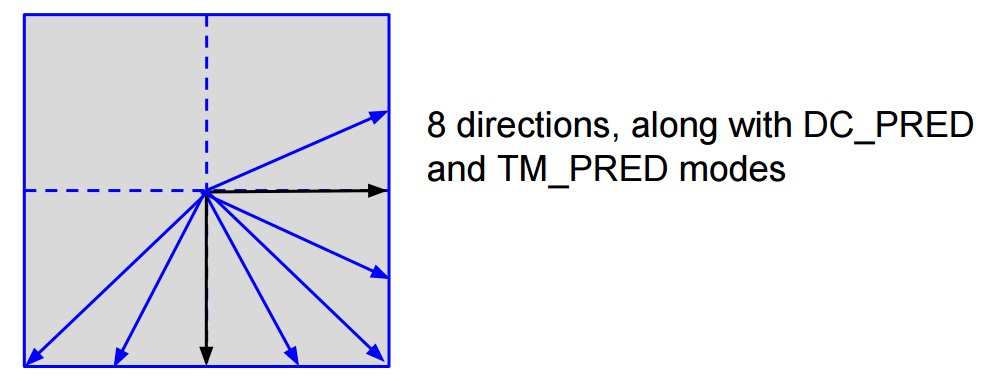
Intra prediction is a bit less complex than what offered by HEVC. Intra prediction acts on transformation blocks and there are 8 directional prediction modes and 2 not-directional compared to the 35 modes of HEVC
Inter-prediction
VP9 uses 1/8th pel motion compensation (double the precision of AVC). A novel feature is the possibility to use normal, smooth or sharp 8th pel interpolation filter (+bilinear). The proper version of the filter can be changed at block level.
Because of patents VP9 doesn’t use bidirectional motion estimation and compensation, so each block has normally only a single forward motion vector. However VP9 uses “compound prediction” where there are two motion vectors and the two predictions averaged together. To avoid patents, “compound prediction” is enabled only on not visible frames (commonly referred as “AltRef”). AltRef can be “constructed” during decoding, are not visible but can be used later as references. Since it’s possible to anticipate in an AltRef a future frame and use it as reference in compound mode, VP9 officially has no B-frames but in fact it has something completely equivalent.
Motion vectors in a frame can point to one of three possible reference frames usually named Last, Golden and AltRef. Ref frame to be used is signaled at 8×8 granularity. The decoder holds a list of 8 reference frames (slots) from which Last, Golden and AltRef refs are choosen at frame level. After decoding, the current frame can (optionally) substitute one of the 8 slots in the pool. An interesting feature of VP9 is the possibility to scale down frames during encoding (not on iframes). Inter predictors and reference frames are scaled accordingly.
Motion vector prediction is similar in complexity to HEVC. A 2-entry list of predictor is build during encoding and decoding. The first predictor is based on surrounding blocks, the second on previous frame. In case of empty list a vector 0,0 is used. So for each block the bitstream can signal to use:
-the first predictor plus a delta
-the first predictor as is
-the second predictor as is
-simply use motion vector [0,0]
Loop Filter
There are 3 possible filters at different strength. VP9 makes a flatness test at boundaries of blocks and if the result is higher than a threshold, one of filter is applied to conceil blockiness.
Segmentation
Segmentation groups together blocks with similar characteristics. It is possible to change some encoding techniques at group level. This feature is dedicated to implement encoding optimizations (including psycovisual optimizations) and require an active support in the encoder.
Profile
The standard VP9 (profile 0) supports only a 8bit – 4:2:0 color mode while the (optional for hardware) profile 1 supports also 4:2:0 / 4:4:4 and optional alpha. In August 2015 Google has released a new version of the reference encoder capable to support the new profile 2 profile 2 (10-12bit -4:2:0) and profile 3 (10-12bit -4:2:2 / 4:4:4 + alpha). Profile 2 is aimed at supporting HDR video in Youtube (expected for summer 2016).
VP9 compared to HEVC
From a technical point of view, VP9 appears to be very near to HEVC as potential efficiency. The actual performance depends by the efficiency of the real encoders, but VP9 has all the potentialities to reach (almost, see below) the same performance of HEVC.
VP9 is a bit sub-par in terms of intra frame prediction (less modes) and of entropy coding (static tables vs adaptive). HEVC appears also to have an higher number of modes and small strategies to reduce the cost of syntax and signaling as well as residuals but on the other end, VP9 has some interesting potentialities in psycovisual optimizations and rate-control thanks to segmentation and adaptive frame resolution.
We will see in the next post the level of efficiency now reached by VP9 encoder compared to AVC and HEVC and the level of maturity of the respective ecosystems.
