Online Video: infancy, youth and maturity
Over the last decade the consumption of online video has undergone an exponential growth, but online video is as old as the Internet itself. Recently Dan Rayburn has published a blog post about the early history of the streaming media industry, an “era” (1995-2005) where pioneers started experimenting codecs, products and models for the distribution of video over the Internet.
But it’s only with the launch of Youtube (2005-2006) that online video started a really tumultuos growth to become the preminent portion of global IP traffic. The ride of online video has been so intense that today the traffic generated by video is more than 70% of the total Internet traffic, orders of magnitude higher than 10 years ago (and still growing…).
We can say that nowadays online video has entered a phase of maturity. It is a multi-billion business ran not only by giants tech companies like Youtube, Netflix, Facebook, Amazon, Hulu, Apple, Vevo, but also by a multitude of traditional broadcasters (BBC, HBO, Sky just to name a few) with their regional OTT services.
The pressure of competition is now really high and this will bring many benefits to end users on many fronts, even that of QoE’s optimization.
Why optimize video streaming ?
Infact, until very recently, no one really cared about video optimization. Like any business in its early stages it was more important to place on the market the right product (and then find a viable business model before running out of money) than anything else including optimization of QoE. Simply put: If it worked it was enough.
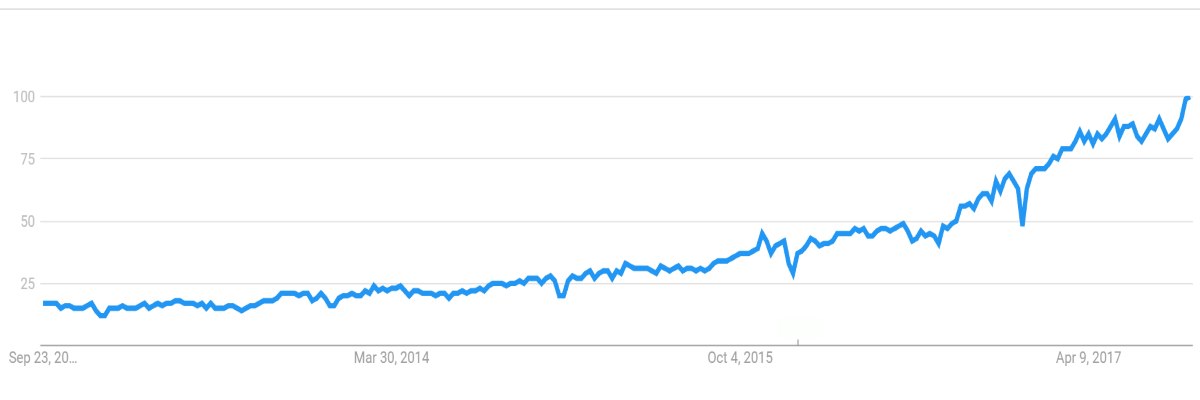
But now things have changed. It cannot simply “work”, user expectations are constantly growing and it’s increasingly harder to engage users (see graph below). In this scenario optimization of streaming is becoming a key technological factor to differentiate a service from competitors, increase the satisfaction / retention and reduce costs.


Source: Conviva CSR2015 -How Consumers Judge Their Viewing Experience
How to optimize ?
If it’s clear what are the reasons to invest in streaming optimization on the other hand it’s not so easy to find the right way(s) to accomplish it. Users push the play button and want only to watch their preferite video flowlessly. But we know that behind-the-scenes there’s a lot of work to do to maximize that user experience. It’s a tangle of codecs, streaming protocols, multiple DRMs and CDNs, advertising, interactions flows, personalized experieces and so on.
At the end of the story, users want the max possible quality through out the video, a fast start and zero rebuffering on every screen. It’s up to us to untangle the skein and fulfill those expectations.
The points to be optimized are many but, in my opinion, the three more important are:
1. Video encoding optimizations (Quality)
2. ABR streaming optimizations (Robustness of distribution)
3. Playback optimizations (Reliability of streaming, start time, other aspect of QoE)
I have touched those points many times in the last 8 years in several projects (optimization of encoding pipelines and/or codecs, optimization of streaming protocols and servers, optimization of players) or during conferences (see Adobe Max 2009 / 2010 / 2011) and I’ve made “online video optimization” one of my distictive competencies.
In general, the matter is complex, the variables are multiple and there are also many boundary conditions so there’s no single recipe. Maximize the QoE requires the coordination of “optimization campaigns” in each of the aforementioned areas.
This requires flexible instead of static approaches, open-mindness instead of dogmas, desire for excellence (both for consultant and customer, paradoxically not so common to find in the latter), but also a mix of scientific approach and inspiration, remembering always that success is in the detail.
Create coordinated optimization strategies in encoding, delivery chain, and players is very complex so in this article I want to talk mainly about encoding optimization. This topic has become hot recently because of this post on the Netflix’s blog. They call it “Per-Title Encode”, I call it “(Content) Adaptive Encoding”.
I have worked on this topic for many companies like for example NTT Data, Sky Italy, Intel Media (acquired by Verizon), EvntLive (acquired by Yahoo!) and lately Vevo. I recently co-authored this article on Vevo’s tech blog on how we have optimized encoding of 200.000+ videos in Vevo during 2015. I suggest to read that article to have an high level introduction of the next topic: Content Adaptive Encoding.
Adaptive Encoding
“All fixed set patterns are incapable of adaptability or pliability. The truth is outside of all fixed patterns” Bruce Lee
Encoding Video is a very complex process.There’s often the temptation to over-simplify complex things and encoding is not an exception. So usually everyone encode video with a predefined set of parameters that satisfy some requirements (usually quality and/or target bitrate). But why should we use a single set of parameters (resolution, bitrate, encoding profiles) when we have very different kind of video and/or playback conditions ?
Static solutions to complex problems are rarely capable to produce best results. If we have mutable conditions and mutable data we need to adapt to them if we want to get closer to the optimal solution.
To exemplify the concept let’s make a parallelism with the problem of “function approximation”. If we need to approximate an arbritary function (see picture below), how can we hope to have a useful solution using a single 0-order approximation (red line on the left) ? It is too coarse, and the error that we get using it is very high (at least in some situations, i.e. for x -> 0). It’s clear that a first order approximation would be better (green line on the left) but still sub-optimal. Like in many other situations it’s even more useful to partition the problem in smaller (simpler) ones, in this case also a set of simple 0-order approximations (red lines on the right) would be considerably better at estimating the function than the original, ultra simplified approach, not to mention a “set” of first-order approximations (green lines on the right).
The partioning of the problem’s domain helps to avoid over-simplifications
 Making a parallelism between this problem and the encoding, approximate with a 0-order estimator is similar to encode everything with the same resolution-bitrate “mix” (a.k.a ABR ladder).
Making a parallelism between this problem and the encoding, approximate with a 0-order estimator is similar to encode everything with the same resolution-bitrate “mix” (a.k.a ABR ladder).
The one-fits-all solution is simple, but far away from being optimal. We must be “Adaptive” in the sense of elaborating dynamic strategies to optimize the system.
There are many ways to optimize encoding but my preferite is, like said above, to partition this multi-dimensional problem in to sub-domains or clusters. We have not to apply necessarily rigorous math, it’s often more a matter of common sense. If we have a complex problem, let’s try to break it down to simplier pieces, easier to solve.
For example, in the case of encoding for ABR, we have commonly video with different complexities (a first variable to analyze) and we watch video on different devices (a second variable to take into account). A static ladder (for ABR streaming) is usually designed for the worst case and like a 0-order provides a sub-optimal performance.
Complexity-Aware encoding
We know that low complexity videos (like talking heads or fixed camera videos) are indeed much easier to encode than complex videos (like sports or action movies). This is inherently related to the way modern codec compress video data. They exploit temporal and spatial redundancies. Simple motion can be predicted from past frames and high spatial frequencies are stripped away by quantization.
A low complexity content can be compressed much more than a complex one, and this with approximately the same perceptual quality.
This is a first partition we can apply to the problem. Let’s classificate the content according to the complexity and apply specific encoding setups to optimize the overall performance toward desired goals.
Do you want to save bandwidth globally ? Why not encode content at different bitrates according to their complexities ? You will have a consistent perceptual quality but savings in bandwith consumption, globally.
You want higher average quality ? In this case, let’s encode simplier content at higher resolutions compared to the resolution we would use using a single, static setup that’s usually calibrated on the worst case (which is high complexity).

Medium Complexity (click to enlarge): 540p@2.4Mbps (left) vs 720p @2.0Mbps (right)
Finding the right recipe is not easy because things may get more complex if we go down in this process. For example, complexity is not a scalar property of a video but a local attribute (complexity can change frame by frame, or at least scene by scene). If we join this with the fact that we may have constraints set by other elements of the pipeline the logic with which we try to approximate the optimal solution may become complex.
Just to make an example, in ABR streaming we are usually forced to encode video in capped VBR (if not CBR) because of player’s heuristic (this is why I’ve said before that the “final” optimization would be to set coordinated optimization strategies for encoding, distribution and playback. You need usually an optimized player to handle VBR encodings).
So to improve the optimization level, we may need to consider not only the average complexity, but also the maximum complexity through-out the video and apply dynamic parameterizations accordingly. Furthermode, complexity may be spatial (high frequencies in the image due to nitid picture or noise) or temporal (high level of motion, more difficult to encode for traditional codecs based on motion estimation and compensation). Different complexities deserve different weights inside our “optimization function” and specific parameterizations.
Viewing Context-aware encoding
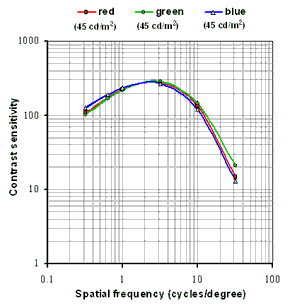
Another variable is represented by the viewing conditions. Why apply the same resolution-parameterization for the same level of bandwidth when the video is watched on quite different screens ? The human eye has a specific angular resolution, so small defects in the picture quality are not visible at high DPI (like that of a smartphone) while the same is not true for low DPI screens like that of a TV. Mix that with the variable distance of viewing and we have another set of variables that we can optimize encoding for.

Example of different sensitivity of vision. The pictures above simulate the playback of the same video at different screen sizes: approx a smartphone screen for the upper image and a tablet (double diagonal) in the lower, cropped image. The picture is the same, simply enlarged. Note that artefacts of encoding are very visible on the lower image, but much less in the upper.
Considering the different sensitivity to artifacts of the eye at different DPI we can optimize the ABR ladder with resolutions-bitrates-parameterizatons specifically choosen to conceal artifacts in specific viewing conditions.
Closing Notes
There are other interesting aspects that enter in the mix of strategies that you can use.
I have no time to analyze them here, but they worth a mention:
– Multi-Codecs encoding: leverage the best codec available on each platform. ie. VP9 on Android / Chrome / FF, HEVC on 4K TVs and H264 every where else.
– VBR vs CBR: use VBR whenever possible. This requires custom player so i.e. is feasible today in DASH for Android and Browser but not for HLS in iOS. Will require multiple encodes but may worth the effort.
– Another interesting topic is the distance and number of renditions inside an ABR ladder. Different network conditions (i.e. mobile vs broadband) may require different setups.
– Special renditions: sometimes I have defined special renditions for special cases that may have specific goals and characteristics (i.e. special renditions to speed up initial buffering efforts).
Concluding, if we mix various strategies, the improvement in QoE and bandwidth consumption may be considerable. Consider that optimize quality/bitrate ratio generates always an increase in QoE both directly and indirectly. Infact, with giants like Netflix that monopolizes the bandwidth (40+% of Internet traffic in USA at peak times) the services that are not optimized will start to suffer (or probably are already suffering). ABR streaming cannot be used any longer an “alibi” for un-optimized encoding, it’s no longer sufficient to be in the market, you’ve to master technology, smooth edges and give the maximum to be competitive. It’s time to optimize.