Without doubt A.I. is the buzzword of the moment. We can definitely find it used everywhere, ranging from image classification/recognition to language translation, from sentiment analysis to market predictions, not to mention autonomous driving, fitness bands, latest CPUs/GPUs, smartphones and so on. A.I. prophets promise a new era of “intelligent” computing that will disrupt the way we live and use technology.
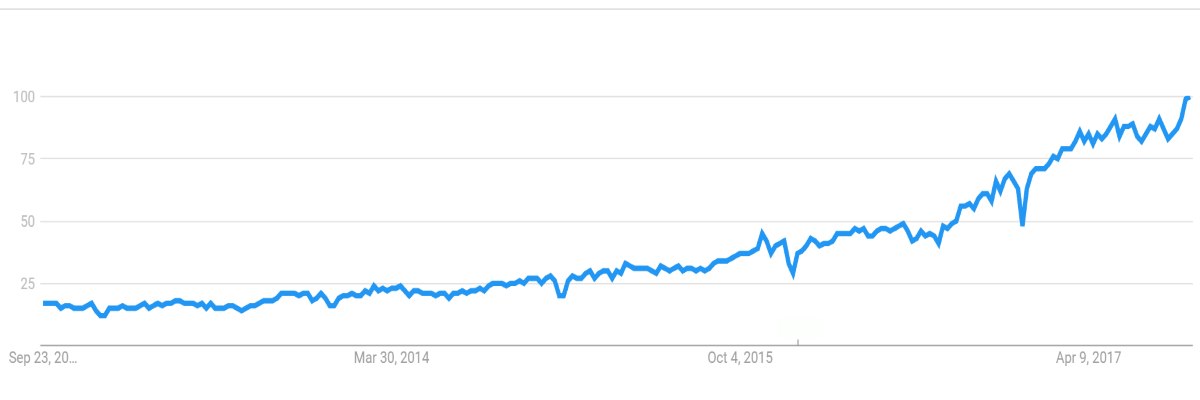
Fig1. Google Trend for “Artificial Intelligence”
Is it all that glorious? Even if all that glitters is not gold and many of the expectations are over inflated I think that A.I. (or it’s more correct to call it Machine Learning for most of the applications) is already truly capable to empower engineers with new tools and ways to solve problems, make accurate predictions and design complex systems.
As such, why don’t we apply it also in the field of encoding and streaming optimization?
but let’s start from the beginning…
Artificial Intelligence Machine Learning
From now on I’ll speak about Machine Learning and not Artificial Intelligence. AI is more a marketing slogan than an accurate term to depict current achievements (read this maybe oversimplified yet efficient comparison). In fact, many of the applications often branded as AI-driven are indeed more simply based on ML algorithms.
Not to mention that now that AI is at its peak of inflated expectations in the Gardner’s hype cycle, a lot of more traditional technologies are opportunely rebranded with the new, bold term just to exploit the wave.
ML is not indeed new. It is rooted in the late 50s and 60s when scientists started to study algorithms that can “learn” from data and make predictions based on that data. Algorithms capable to model complex systems from sample inputs and make data-driven predictions or classifications without active modeling by engineers.
ML is based on or is adjacent to other well know disciplines like computational statistic, mathematical optimization, operation research, linear programming; All popular university courses in not so ancient times.
ML has been widely used in the industry for years with success. Every time you use your credit card, a ML-based algorithm estimates the probability of a fraud thanks to classification algorithms trained on a huge amount of transactions (someone has said BigData?). Recognition of digits, OCR, speech recognition, spam detection are other consolidated applications. More recently you find ML-based algorithms in fitness bands to recognize/classify the activity done by users. Netflix has created a famous recommendation engine using ML. Google uses ML extensively for speech recognition, search ranking, form completion, translations. Apple uses it for Siri, among other things and any image classification application is based on deep learning and CNN that are at the cutting-edge of ML.
So it’s true that ML is powerful but it’s nothing exotic. It is essentially a discipline that provides algorithms, methods and best practices that help engineers in creating complex models without analyzing necessarily the underlying phenomena.
Indeed, modeling is something engineers already often do in their daily work. But sometimes analyze and modelize a complex phenomenon is not easy at all. I have already talked about optimization approaches and complex modeling in this post. At the end, instead of studying a complex system by inferring the rules of its subsystems (a classic way to proceed), ML provides engineers with a set of tools to create much more accurate models starting from a wide number of observations and data.
There are many algorithms, techniques, procedures and approaches in ML. A broad distinction is made between supervised learning, unsupervised learning and reinforcement learning. And inside supervised ML we can mention algorithms like linear regression/classification, Support Vector Machine, Random Forest, Decision Trees, Ensemble Methods, Gradient Boosting, Ada Boost and so on, and then continue with the Neural Networks family: Deeplearning, Convolutional NN, Recurrent NN, LSTM RNN, etc…
Wow, it’s a wide and complex landscape where it’s not simple and immediate the choice of the algorithms, the fit and the optimization of the entire system.
There are important points to considerate:
1. ML is a tool-set but then is up to the engineers how to use it in creative and efficient manner. ML doesn’t work by itself!
2. Many ML-algorithms behave like a black-box and it is not easy to extract knowledge of the underlying phenomena from that black-box. Sometimes is preferable a simpler algorithm than a more complex (and more efficient) one when you want to better comprehend the system under study.
3. Overfitting is everywhere! It’s the worst enemy and requires much attention especially to avoid creating models that in reality perform worse than empiric approximations.
Machine Learning as a tool to optimize video encoding
In this post I compared optimization to function approximation/estimation. It’s easy to see the parallelism between function approximation and ML-based regression techniques. Using ML is possible to create a model that “predicts” with a good accuracy the behavior of a system for unknown inputs using only a number of known sample points to train/fit a chosen ML algorithm and minimize the associated cost function.
A mix of ML algorithms can be very useful everytime you have to “optimize” something.
Minimize a cost function means, in fact, optimize and we have already said that ML is based on mathematical optimization, operation research and linear programming, disciplines strictly correlated to the concept of “optimization”.
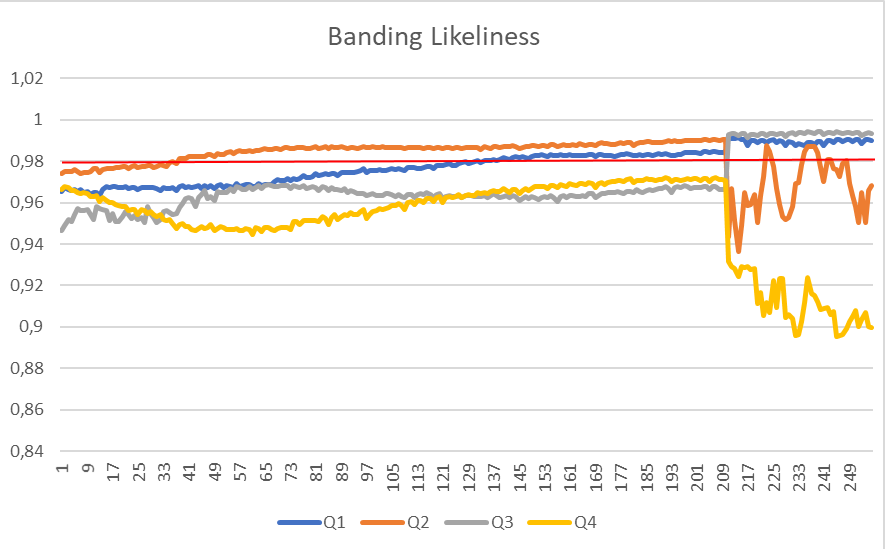
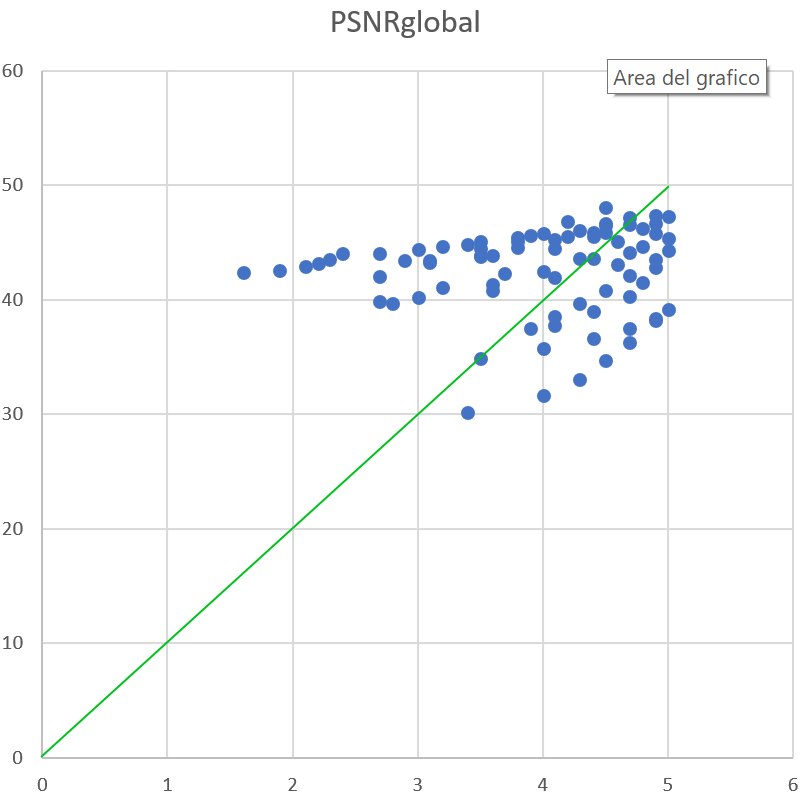
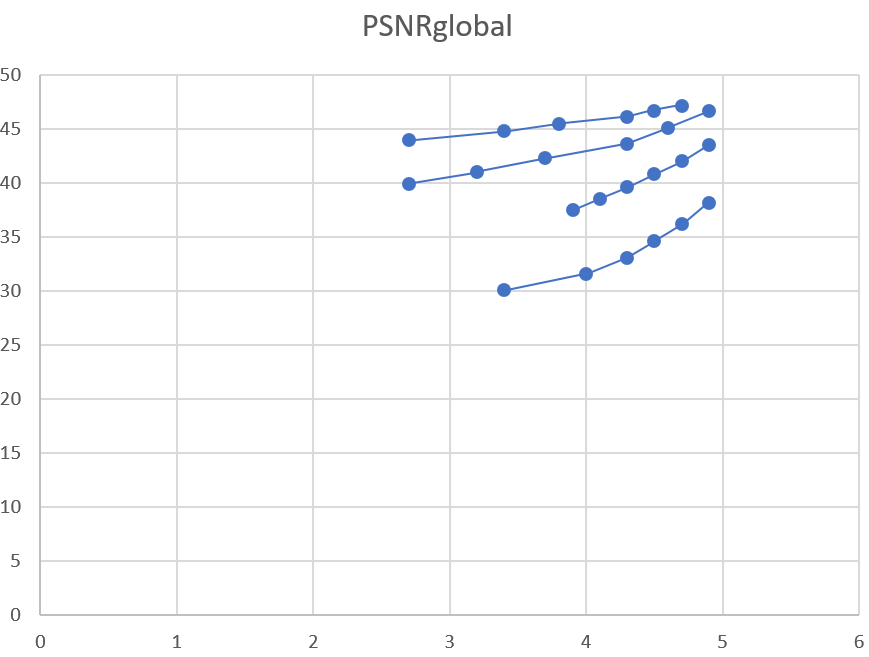
So even video encoding is a fertile field for ML-driven optimization. In video encoding, we have many independent variables (metrics that describe the features of the video, resolution, target quality, etc…) and the final objective could be (but not only) to minimize quality/bitrate ratio using the right encoding parameterizations.
In recent years Youtube and Netflix have used ML to achieve optimization of specific objectives in video encoding. In the case of Youtube, they have used NN to predict quantization levels that produce the desired target bitrate so to be able to obtain the performance of a dual pass encoding in a single pass. This is an example of optimization of the quality/speed ratio because in the Youtube’s scenario the huge amount of input videos determines a high cost of encoding that this approach tries to optimize.
Netflix has instead used ML (SVM in the specific case) to fuse the performance of elementary objective metrics in a unique reliable subjective quality estimation (VMAF metric, Video Multi-Method Assessment Fusion). VMAF has been used then as an enabling technology for other optimization processes.
Content-Aware to the next level: Perception-based encoding
In the last year, I’ve been involved in an extensive and on-going project of NTT Data that uses ML to optimize encoding. The objective of the project is to take Content-Aware encoding to the next level and be able to encode with a target perceptual quality on screens of different size. I already introduced this as a new emerging trend in a previous blog-post.
Instead of specifying a resolution and bitrate, like in a traditional encoding, now we can specify only the target perceptual quality (es: a MOS rate from 1 to 5) and the max size of the screen on which the video has to be watched. The ML-driven algorithm will determine the encoding parameterizations for each scene of the video to achieve the desired perceptual quality when watched on that target screen size. A high complexity scene will require a higher average bitrate while a low complexity scene will require a lower bitrate. But the actual value and many parameters will depend on input content metrics, target MOS and target screen size.
Such a level of optimization provides a way to minimize the bandwidth consumption using only the amount of bits necessary to achieve the desired level of quality across different screen sizes. At the same time, using advanced player’s heuristics is possible to exploit the VBR encoding produced in output to increase also the QoE during streaming, delivery in average an higher quality compared to traditional types of encoding (es: CBR o capped VBR with a target avg bitrate).
The project has required a massive campaign of subjective quality assessment performed on screens of various size. More than 14.000 quality rates related to human perception have been analyzed, enriched and used to train an ensemble of ML-algorithms. A variable set of elementary metrics (from 4 to 12) are used in different point of the project to characterize sources, encoded videos and codecs’ performance and form the vector of input features for the predictors.
The first working version of this system is going to be used by an important broadcaster in Europe and the results are very promising. For example, thanks to the training with perceptual ratings collected selectively on TVs/Tablets/Smartphones, the average bitrate of a typical TV series like Game Of Thrones with a target MOS of ~4.2 (good in a 1-5 scale) is just 350Kbps on smartphone, 900Kbps on Tablets and 2.1Mbps on TVs, down -64%, -50% and -30% respectively from the bitrates of the previous static profile.
Conclusions
ML is really a precious ally when developing optimizations in a wide range of scenarios. Previously I used to use empirical approximations that worked well but in a sub-optimal way. Now ML allows a better fitting even if it may require a considerable amount of data to work properly.
The next steps are to increase the accuracy and performance of the pipeline, but I’m also exploring the use of ML on the player side of the equation, to optimize even more also ABR heuristics and player’s logic.