In the last years, I’ve been involved in interesting projects around how to measure and/or estimate perceptual quality in video encoding. Measuring quality is by itself useful during encoding optimizations development and monitoring to assess the benefits of an optimized pipeline. But it’s even more interesting to estimate quality you can achieve with specific parameters before encoding so to be able to implement advanced logic in Content-Aware Encoding.
It’s a complex topic but I’d like to focus in this post on the role that PSNR can still have in measuring quality.
Is PSNR not much correlated to perception?
PSNR is well known to be not much correlated to perception. SSIM is a bit better but both show to be scarcely correlated from a general point of view, or at least so it seems:
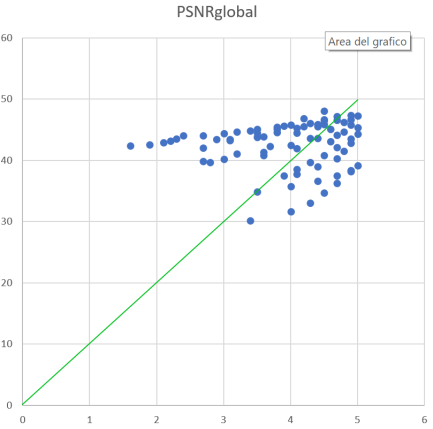
The scatter-plot shows a number of samples encoded at different resolutions and levels of impairment and PSNR vs MOS (perceptual quality in standard TV-like viewing conditions). You can see that the relationship between PSNR and MOS is not very linear and for example a value of 40dB corresponds to MOS ranging from 1.5 to 5, depending on the content.
It is clear that we cannot use PSNR as an indicator of absolute quality in an encoding. Only at very high values, like 48dB the significance of the measure is useful.
It is because of that scarce correlation with MOS (the optimal metric would stay on the green line in the graph above) that Netflix has defined a metric like VMAF.
VMAF uses a different approach: it calculates multiple elementary metrics and using machine learning build a “blended” estimator that works much better than the individual elementary metrics.
I have worked on a different, but conceptually similar, perception-aware metric in the past. So I know that such metrics may have a problem: are a bit expensive to calculate. This is not because of ML that’s very fast when inferencing, but because you need to use accurate and slow elementary metrics (or a higher number of faster metrics) to have good results in the estimation.
Can PSNR still play a role?
In the common experience, PSNR still communicates something to the compressionists. Professionals like Jan Ozer continue to advocate PSNR for certain type of assessment and I agree that, for example, it is very appreciable especially in relative comparisons, probably thanks to its “linearity” inside specific testing frames. Knowing how ML based metrics work, I admit that PSNR is much more linear and monotonic “locally” while this is not guaranteed in case of ML-based estimators (it depends heavily on the ML-algorithm).

So, let’s take a look at this scatter plot. The cloud of points provides little information but if we connect the points related to the same video source we see that a structure starts to emerge.
The relationship between PSNR and MOS for the same source can be linearized in the most important part of the chart with an error that in some project can be negligible.
So what we are lacking to use PSNR as a perceptual quality estimator?
We need some other information extracted from the source that provides us with a starting point and a slope. With a fixed point on the chart (es: the PSNR needed to reach 4.5 MOS for a given source) and a slope (the angular coefficient of the approximated linearization of the PSNR-MOS relationship for that specific content), we could be able to use PSNR as an absolute perceptual quality estimator simply projecting the PSNR to the line and recovering the corresponding MOS.

Now I’m experimenting exactly around how to quickly find a starting point and a slope from the characteristics of the specific source (scene by scene, of course). The objective is to find a quick method to estimate those params (point and slope) so to be able to measure absolute perceptual quality an order of magnitude quickly than with VMAF (probably with lower accuracy too, but still with good local linearity and monotonic behavior).
This may be very useful in advanced Content-Aware Encoding logic to measure/estimate the final MOS of the current encoding and, for example, adjust params to achieve the desired level (CAE in live encoding is the typical use case).
